Building a Data Pipeline with Azure Data Factory: Step-by-Step Guide
In today’s data-driven world, organizations need robust solutions to collect, transform, and deliver data from various sources to target systems. Microsoft’s Azure Data Factory (ADF) stands out as a fully managed, cloud-based data integration service designed for creating scalable and reliable data pipelines. This step-by-step guide will walk you through the essentials of building a data pipeline using Azure Data Factory, helping you lay a solid foundation in real-world data engineering practices.
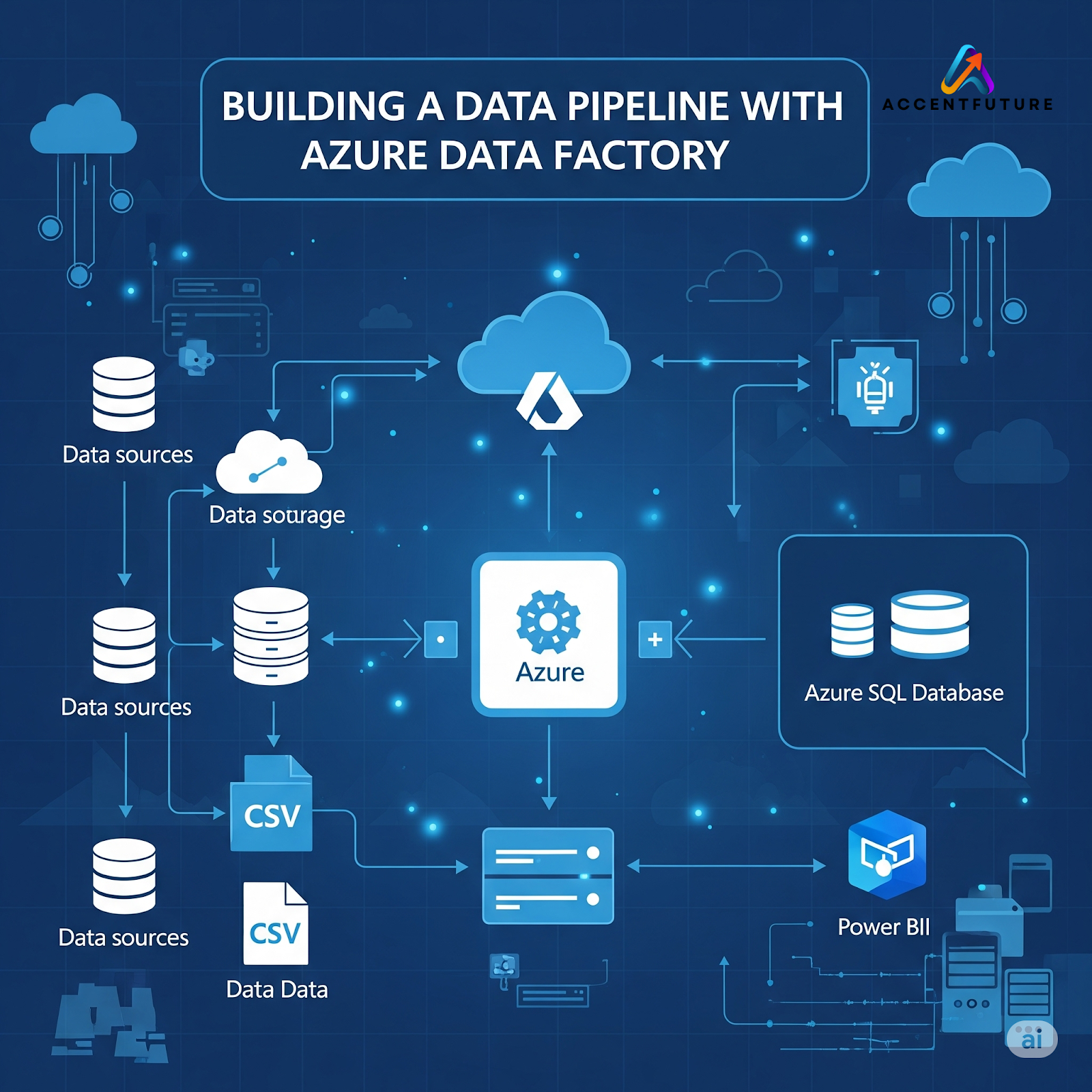
At AccentFuture, we empower learners through hands-on training in cloud data integration tools like ADF, ensuring they’re job-ready for the modern data landscape.
What is Azure Data Factory?
Azure Data Factory is a serverless data integration platform that allows you to create, schedule, and orchestrate data pipelines at scale. It enables seamless movement of data between on-premises and cloud sources and supports complex transformations through data flows or integration with services like Azure Databricks or HDInsight.
Step-by-Step Guide to Build a Data Pipeline
Step 1: Create an Azure Data Factory Instance
Start by logging into the Azure portal.
Navigate to “Create a Resource” → “Data + Analytics” → “Data Factory.”
Choose your subscription, resource group, and region.
Provide a name for your Data Factory instance.
Click “Review + Create”, then “Create.”
This will provision your ADF environment.
Step 2: Set Up Linked Services
Linked Services act as connection strings to your source and destination systems—these could be Blob Storage, Azure SQL, REST APIs, or even Amazon S3.
In the ADF UI, go to the “Manage” tab.
Click “Linked Services” and then “New.”
Choose your source (e.g., Azure Blob Storage) and configure the credentials (via account key, SAS, or managed identity).
Repeat this for your destination service.
Step 3: Create Datasets
Datasets represent the structure of data you’re moving. For example, if you're copying a CSV file from blob storage, you’ll define a dataset with the file path, format, and schema.
Under the “Author” tab, click “+” → “Dataset.”
Select the appropriate format (e.g., DelimitedText, Parquet, SQL table).
Point it to your linked service and configure folder path, file name, and schema details.
Step 4: Build the Pipeline
Now comes the main step—creating the pipeline itself.
Go to Author → Pipelines → +New Pipeline.
Drag and drop activities like “Copy Data,” “Data Flow,” or “Lookup” from the Activities pane to the canvas.
Configure each activity:
Source: Choose the source dataset.
Sink: Define the destination dataset.
Mapping: Map fields from source to destination if needed.
You can also chain multiple activities with conditional execution, loops (ForEach), or parameterized triggers.
Step 5: Test and Debug the Pipeline
ADF provides built-in debugging tools.
Click “Debug” on the pipeline canvas.
Monitor the output logs to verify the data flow.
Check for errors like connection failures or schema mismatches.
Step 6: Create a Trigger
To automate your pipeline, you can schedule it using time-based or event-based triggers.
Go to Triggers → New/Edit.
Set the trigger type (e.g., scheduled daily at midnight).
Attach it to the pipeline and activate.
This will make your pipeline run automatically without manual intervention.
Step 7: Monitor Pipeline Execution
Once your pipeline is live, monitor its performance and status:
Go to the Monitor tab in ADF.
View pipeline runs, activity runs, and trigger runs.
Inspect logs and export run history for auditing.
Monitoring helps ensure your pipeline operates efficiently and enables rapid troubleshooting in case of failure.
Real-World Use Cases
Azure Data Factory can be used for:
Migrating on-premise SQL Server data to Azure Synapse.
Consolidating data from multiple SaaS apps like Salesforce and Google Analytics.
Powering business intelligence dashboards with real-time data refresh.
Running ETL processes for big data analytics.
At AccentFuture, we cover these use cases extensively in our Azure Data Factory online training, giving learners the confidence to build enterprise-grade data solutions.
Final Thoughts
Azure Data Factory simplifies the creation of complex data pipelines, enabling seamless data movement and transformation across hybrid environments. By following the steps outlined above—setting up linked services, defining datasets, building and testing the pipeline—you’re well on your way to becoming proficient in data integration.
Whether you're a data engineer, BI developer, or aspiring cloud professional, mastering ADF is a valuable skill. For hands-on training, expert mentorship, and real-time projects, explore the Azure Data Factory courses at AccentFuture and elevate your data career to the next level.🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: contact@accentfuture.com
🌍Visit Us: AccentFuture
related blogs:
https://www.accentfuture.com/optimize-sql-server-docker/
https://medium.com/@sssiri242/getting-started-with-azure-data-factory-for-etl-pipelines-d06be3419e96
https://software086.wordpress.com/2025/04/23/securing-data-in-azure-encryption-rbac-and-compliance/

Comments
Post a Comment