Building Pipelines with Azure Synapse
By AccentFuture – Empowering Future Data Engineers
In today’s data-driven world, seamless data movement and transformation are critical to building efficient analytics solutions. Azure Synapse Analytics stands out as a powerful platform that simplifies big data processing, real-time analytics, and data pipeline creation. Let’s dive into how you can build data pipelines using Azure Synapse, and why it’s an essential skill for modern data engineers.

🚀 What is Azure Synapse?
Azure Synapse is Microsoft’s integrated analytics service that brings together big data and data warehousing. It allows you to query data using serverless or provisioned resources and provides end-to-end solutions for ingestion, preparation, management, and visualization.
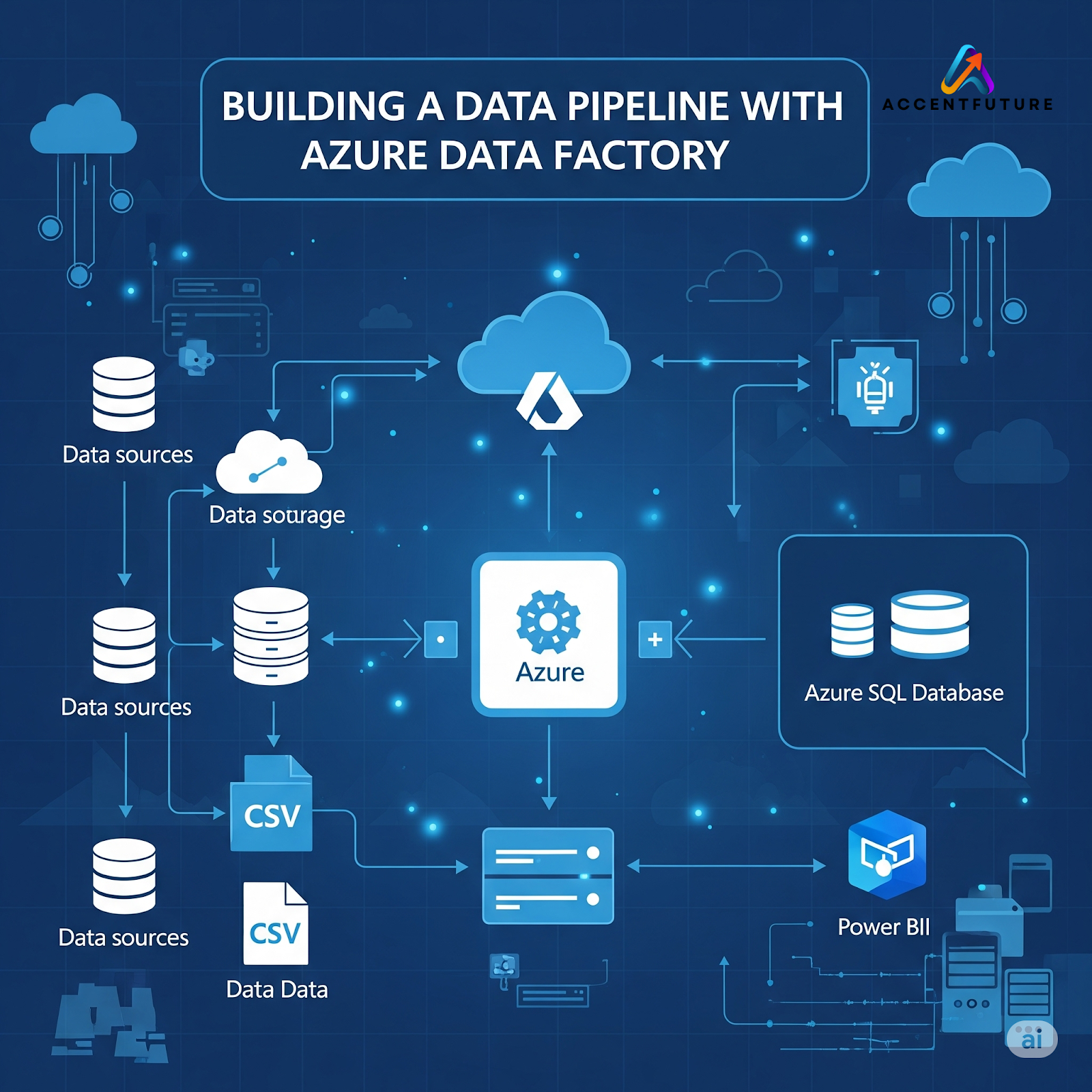
🔧 Why Use Azure Synapse Pipelines?
Azure Synapse Pipelines (built on Azure Data Factory) allow you to:
Ingest structured & unstructured data
Orchestrate complex workflows
Automate data movement across services
Integrate with Power BI for real-time dashboards
Schedule data refreshes and transformation tasks
🛠️ Building a Simple Pipeline: Step-by-Step
Here’s a simple walkthrough to create a pipeline in Azure Synapse:
Step 1: Launch Synapse Studio
Navigate to Synapse Studio in the Azure Portal. It’s a unified environment for managing everything from data ingestion to visualization.
Step 2: Create a New Pipeline
Go to Integrate > Pipelines > + New pipeline.
Name your pipeline, e.g., "IngestSalesDataPipeline".
Step 3: Add a Source Dataset
Define your source – this could be an Azure Blob, SQL Database, or even a REST API. Choose a Linked Service and specify the path or query.
Step 4: Add a Sink (Destination)
Define the destination where the data should land. This could be a Data Lake, Azure SQL DB, or Synapse SQL Pool.
Step 5: Add Data Flow or Transformation
Use Mapping Data Flows to apply transformations like joins, filters, or aggregations.
Step 6: Trigger the Pipeline
Add a Trigger to run the pipeline manually, on schedule, or based on an event.
Step 7: Monitor the Execution
Go to the Monitor tab to view pipeline runs, debug errors, and analyze performance.
🌐 Real-World Use Cases
Retail Analytics: Load sales data daily to generate revenue dashboards.
IoT Data Processing: Ingest and transform sensor data for anomaly detection.
Healthcare: Move patient data securely across systems for reporting and compliance.
🎓 Learn Azure Synapse with AccentFuture
At AccentFuture, we offer hands-on training in Azure Data Engineering, including real-time labs on Azure Synapse pipelines. Our expert-led sessions help you master data integration, orchestration, and analytics skills in high demand across the industry.
📚 Enroll Now at accentfuture.com and build your career as a certified Azure Data Engineer.
Related blogs
contacts
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: contact@accentfuture.com
🌍Visit Us: AccentFuture


Comments
Post a Comment